
Cosine similarity is a measurement that quantifies the similarity between two vectors based on the cosine of the angle between them. The vectors are typically non-zero and are within an inner product space.
What Is Cosine Similarity?
Cosine similarity is a measurement that quantifies the similarity between two non-zero vectors based on the cosine of the angle between them. Vectors used in cosine similarity calculations are typically within an inner product space.
A specific project requirement tasked me to explore methods of quantifying the similarity between two or more objects. The objects were two images of humans performing poses. The objective was to quantify how similar the poses in the images were. Trying to solve this problem led me into the world of mathematics, where I stumbled upon a similarity measurement called cosine similarity. I was intrigued by the simplicity of this implementation, and more importantly, it was straightforward enough to understand.
In this article, I will explain the basics of cosine similarity. I’ll also provide several applications and domains where cosine similarity is leveraged, and finally, there will be a code snippet of the algorithm in Python.
Cosine Similarity Explained
Cosine similarity is described mathematically as the division between the dot product of vectors and the product of the Euclidean norms or magnitude of each vector.
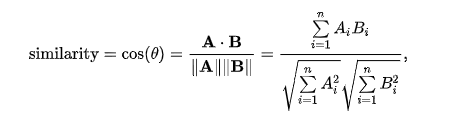
Cosine similarity is a commonly used similarity measurement technique that can be found in libraries and tools such as Matlab, scikit-learn and TensorFlow, etc.
Below is a quick implementation of the cosine similarity logic in Python.
#import NumPy library
import numpy as np
#create function to compute cosine similarity
def cosine_similarity(vector1, vector2):
#calculate dot product between vector1 and vector2
dot_product = np.dot(vector1, vector2)
#calculate magnitudes for vector1 and vector2
magnitude_a = np.linalg.norm(vector1)
magnitude_b = np.linalg.norm(vector2)
#calculate cosine similarity and return value
cosine_sim = dot_product / (magnitude_a * magnitude_b)
return cosine_sim
#example vectors to use in equation
vector_A = [1, 2, 3]
vector_B = [4, 5, 6]
#plug vector_A and vector_B into cosine_similarity function
similarity = cosine_similarity(vector_A, vector_B)
#display result of cosine similarity for given example vectors
print("Cosine similarity:", similarity)
#Output: Cosine similarity: 0.9746318461970762Cosine similarity is a value that ranges from -1 to 1, where 1 indicates the vectors are identical and perfectly aligned (with no angle between them), 0 indicates the vectors are orthogonal (90 degrees to each other) with no match and -1 indicates completely opposite vectors (with a 180 degree angle between them).
What Is a Good Cosine Similarity Score?
A cosine similarity is a value that is bound by a constrained range of -1 and 1. The closer the value is to 0 means that the two vectors are orthogonal or perpendicular to each other. When the value is closer to 1, it means the angle is smaller and the vectors are more similar.
In our code example, the similarity measurement is a measure of the cosine of the angle between the two non-zero vectors A and B.
Suppose the angle between the two vectors were 90 degrees. In that case, the cosine similarity will have a value of 0. This means that the two vectors are orthogonal or perpendicular to each other.
As the cosine similarity measurement gets closer to 1, then the angle between the two vectors A and B is smaller. The images below depict these scenarios more clearly.
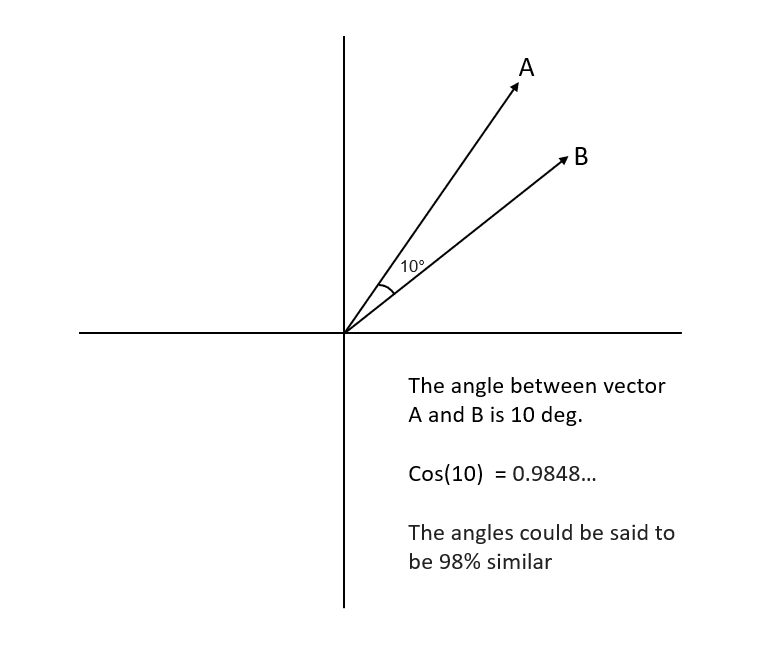
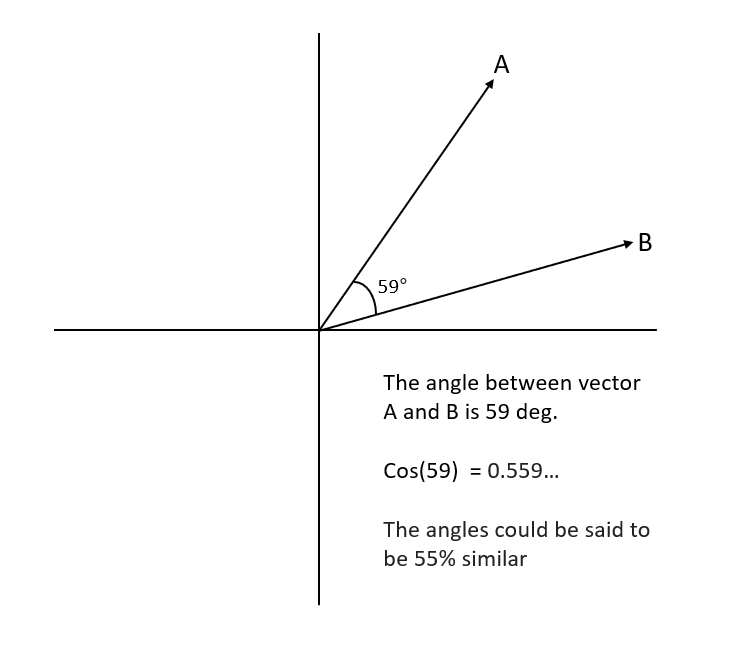
More on Machine Learning: SARSA Reinforcement Learning Algorithm: A Guide
Cosine Similarity Applications
Cosine similarity has its place in several applications and algorithms.
From the world of computer vision to data mining, comparing a similarity measurement between two vectors represented in a higher-dimensional space has a lot of uses.
Let’s go through a couple of scenarios and applications where the cosine similarity measure is leveraged.
1. Document Similarity
A scenario that involves the requirement of identifying the similarity between pairs of a document is a good use case for the utilization of cosine similarity as a quantification of the measurement of similarity between two objects.
To find the quantification of the similarity between two documents, you need to convert the words or phrases within the document or sentence into a vectorized form of representation.
The vector representations of the documents can then be used within the cosine similarity formula to obtain a quantification of similarity.
In the scenario described above, the cosine similarity of 1 implies that the two documents are exactly alike and a cosine similarity of 0 would point to the conclusion that there are no similarities between the two documents.
Here are the two documents we will compare:
- Document 1: "Deep Learning can be hard"
- Document 2: "Deep Learning can be simple"
Step 1: Obtain a Vectorized Representation of the Texts
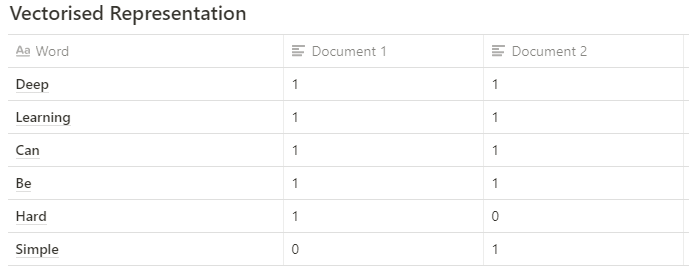
- Document 1: [1, 1, 1, 1, 1, 0] - let’s refer to this as A.
- Document 2: [1, 1, 1, 1, 0, 1] - let’s refer to this as B.
Above we have two vectors (A and B) that are in a six dimension vector space.
Step 2: Find the Cosine Similarity
cosine similarity (CS) = (A . B) / (||A|| ||B||)
- Calculate the dot product between A and B:
(1×1) + (1×1) + (1×1) + (1×1) + (1×0) + (0×1)= 4. - Calculate the magnitude of the vector A:
√(1² + 1² + 1² + 1² + 1² + 0²) = 2.2360679775. - Calculate the magnitude of the vector B:
√(1² + 1² + 1² + 1² + 0² + 1²) = 2.2360679775. - Calculate the cosine similarity:
(4) / (2.2360679775*2.2360679775) = 0.80(80 percent similarity between the sentences in both document).
Let’s explore another application where cosine similarity can be utilized to determine a similarity measurement between two objects.
2. Pose Matching
Pose matching involves comparing the poses containing key points of joint locations.
Pose estimation is a computer vision task, and it’s typically solved using deep learning approaches such as convolutional pose machines, stacked hourglasses and PoseNet, etc.
Pose estimation is the process where the position and orientation of the vital body parts and joints of a body are derived from an image or sequence of images.
In a scenario where there is a requirement to quantify the similarity between two poses in Image A and Image B, here is the process that would be taken:
- Identify the pose information and derive the location key points (joints) in Image A.
- Identify the x,y location of all the respective joints required for comparison. Deep Learning solution to pose estimation usually provides information on the location of the joints within a particular pose, along with an estimation confidence score.
- Repeat steps one and two for Image B.
- Place all x,y positions of Image A in a vector.
- Place all x,y positions of Image B in a vector.
- Ensure the order of the x,y positions of each joint is the same in both vectors.
- Perform cosine similarity using both vectors to obtain a number between 0 and 1.
More on Machine Learning: An Introduction to Classification in Machine Learning
Cosine Similarity Advantages
There are other application domains you might find the utilization of cosine similarity, such as recommendation systems, plagiarism detectors and data mining. It can even be used as a loss function when training neural networks.
The logic behind cosine similarity is easy to understand and can be implemented in presumably most modern programming languages.
One thing I learned from exploring these little segments of math was that most topics are often deemed complex since there aren’t enough resources to teach the topic adequately. If you have the appropriate learning resources and patience, then it’s possible to grasp a large number of mathematics topics.
Frequently Asked Questions
Frequently Asked Questions
What is cosine similarity?
Cosine similarity measures the similarity between two non-zero vectors by calculating the cosine of the angle between them. It is commonly used in machine learning and data analysis.
How is cosine similarity calculated?
Cosine similarity is calculated as the dot product of two vectors divided by the product of their magnitudes.
As an equation, this would look like:
Cosine Similarity = dot product of vector A and vector B / (magnitude of vector A * magnitude of vector B)
What is the range of cosine similarity values?
A cosine similarity value ranges from -1 to 1, where:
- 1 means the vectors are identical (no angle between vectors)
- 0 means the vectors are orthogonal (90 degree angle between vectors)
- -1 means the vectors are completely opposite to each other (180 degree angle between vectors)


